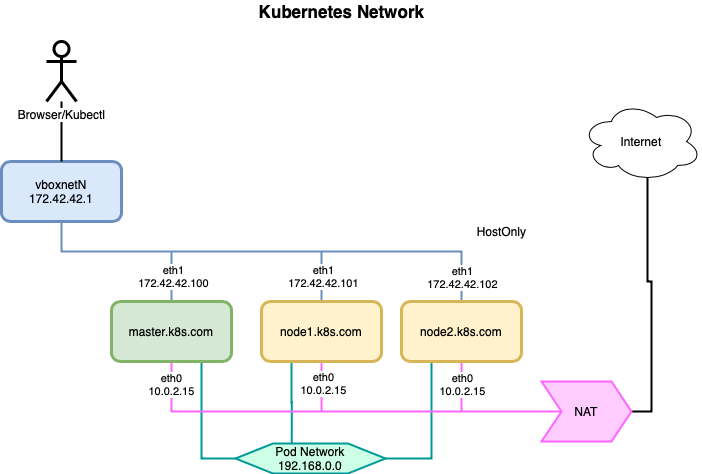
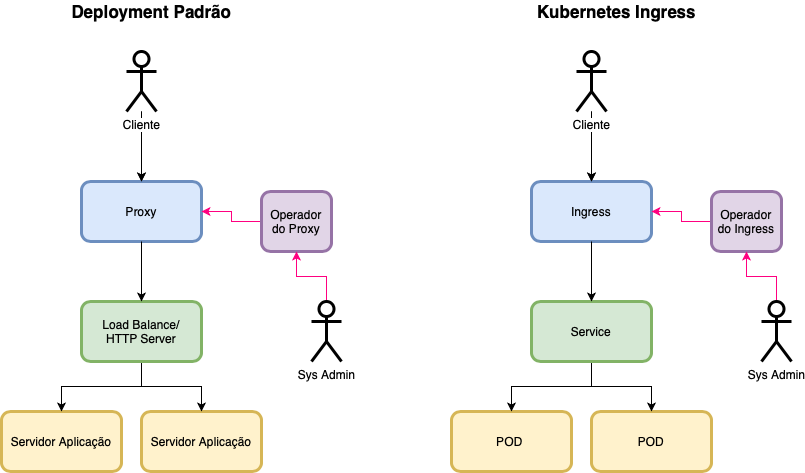
I usually leave the technical parts for my wiki, but this time I had to add this topology here on the blog. Running Sterling B2B Integrator in a container involves a series of pods, services, and network configurations, which can make management a bit tricky. To organize my understanding of the whole structure, I decided to create a diagram to help visualize the interactions.
Below the diagram:
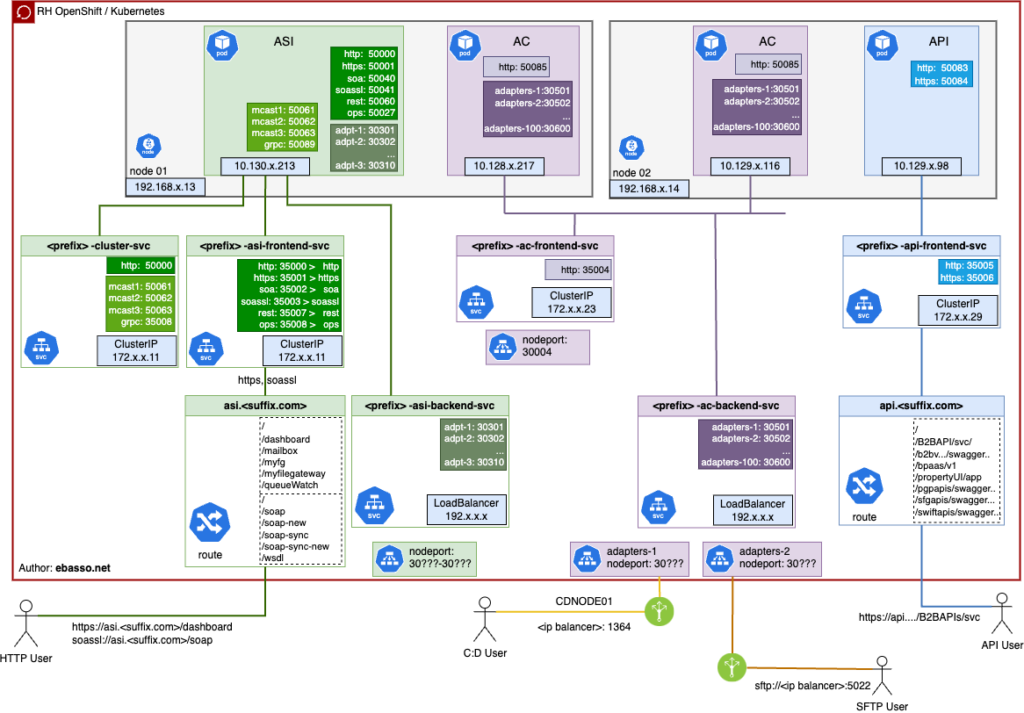
The diagram I created includes all the components, as well as the critical connections that make everything work in harmony. This proved essential for understanding the topology in a clear and intuitive way.