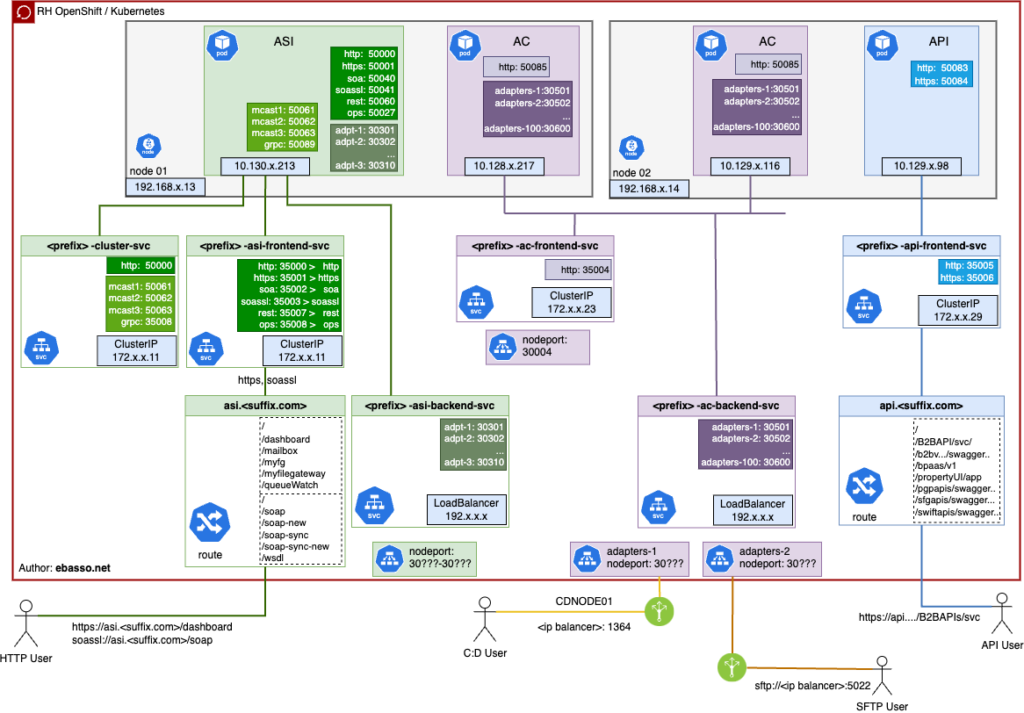
I usually leave the technical parts for my wiki, but this time I had to add this topology here on the blog. Running Sterling B2B Integrator in a container involves a series of pods, services, and network configurations, which can make management a bit tricky. To organize my understanding of the whole structure, I decided to create a diagram to help visualize the interactions.
Below the diagram:
The diagram I created includes all the components, as well as the critical connections that make everything work in harmony. This proved essential for understanding the topology in a clear and intuitive way.
Distribuições Kubernetes Simples e Pequenas para o Edge
Neste artigo descrevo três distribuições Kubernetes compactas para operação em dispositivos de borda (edge) ou em pequenos escritórios. Clusters Kubernetes de produção utilizam vários servidores físicos, mas configurações de nó único também são viáveis, especialmente para desenvolvedores. Há um aumento no uso de dispositivos de borda com ambientes Kubernetes simples.
Essas distribuições permitem gerenciamento centralizado e simplificam o desenvolvimento e testes de aplicações em uma única plataforma: Kubernetes. Exemplos práticos incluem sistemas locais, escritórios isolados, etc.
Distribuições Kubernetes mais potentes como Rancher e OpenShift são difíceis de configurar em um único nó. Assim, fabricantes oferecem distribuições leves para operação em edge, como K3s (SUSE), MicroShift (Red Hat) e MicroK8s (Canonical).
K3s (SUSE):
K3s é a versão menor do Rancher Kubernetes Engine, operando com recursos mínimos (1 núcleo de CPU e 512MB de RAM).
Dispensa a base de dados etcd, usando SQLite, ideal para operação de nó único.
Suporta operação multinó.
Usa Traefik para roteamento IP e Flannel para redes virtuais de pods.
Armazenamento padrão é o Hostpath, mas pode usar outros provedores.
Fácil de instalar em várias distribuições Linux e CPUs ARM64 e x86_64.
MicroShift (Red Hat):
Versão leve do OpenShift, requer 1GB de RAM e um núcleo de CPU.
Utiliza etcd e outros componentes como OVN e TopoLVM.
Instalação depende de pacotes RPM e o gerenciador de pacotes DNF.
Integra com o image builder do OSTree, mas depende de produtos comerciais da Red Hat.
Ainda em fase de desenvolvimento e documentação desatualizada.
MicroK8s (Canonical):
Versão leve do Kubernetes da Canonical, requer 500MB de RAM.
Funções agrupadas como add-ons, sem incluir roteador de entrada ou driver de armazenamento por padrão.
Usa Dqlite em vez de etcd e containerd em vez de CRI-O.
Instalação via Snap, o que complica a depuração.
Não suporta SELinux, apenas AppArmor.
Ferramentas self-built da Canonical podem ser desvantajosas.
Conclusão: Todas as três distribuições oferecem Kubernetes compacto para borda ou pequenos escritórios. MicroShift é bem integrado com OSTree mas ainda está ligado a produtos Red Hat. MicroK8s é fácil de começar mas carece de suporte SELinux e utiliza ferramentas internas da Canonical. K3s é flexível, fácil de configurar, suporta SELinux, e utiliza projetos padrão bem mantidos.
Implantar múltiplas aplicações em Kubernetes/OpenShift pode ser um desafio. Gerenciar configurações, dependências e ambientes diversos pode transformar o processo em um labirinto de complexidades. No entanto, eu firmemente acredito que o processo de instalação deve ser rápido e simples. Com essa crença em mente, gostaria de apresentar a você o repositório https://github.com/ibm-sterling-devops/ansible-ibm-sterling, uma ferramenta que não só simplifica o deployment na plataforma Linux, mas também oferece suporte para Kubernetes e OpenShift, tornando-se uma solução abrangente para implantações modernas de aplicações.
Apresentando o repositório ansible-ibm-sterling
O ansible-ibm-sterling é um conjunto de playbooks e roles do Ansible projetados para automatizar o deployment de aplicações IBM Sterling. Com suporte para implantações em Kubernetes e OpenShift, ele oferece uma maneira simplificada e eficiente de gerenciar e implantar stacks de aplicações complexas em diversos ambientes.
Benefícios do uso do ansible-ibm-sterling
Instalação Rápida e Simples: O processo de instalação é projetado para ser rápido e direto, alinhando-se com minha crença de que implantar aplicações deve ser livre de complicações.
Automação: Esta ferramenta de deployment via CLI automatiza o processo de implantação, reduzindo a intervenção manual e minimizando erros humanos. Isso acelera o deployment e garante consistência entre os ambientes.
Consistência: Garante deployments consistentes em vários ambientes, incluindo clusters Kubernetes e OpenShift, mantendo a integridade e o comportamento da aplicação.
Escalabilidade: Facilmente escalável para implantar grandes aplicações em múltiplos servidores, ambientes de nuvem ou clusters Kubernetes/OpenShift, graças à arquitetura sem agente do Ansible e ao suporte a Kubernetes/OpenShift.
Flexibilidade: Altamente customizável para adaptar o processo de implantação às suas necessidades específicas. A flexibilidade do Ansible e o suporte a Kubernetes/OpenShift permitem que você ajuste o processo de implantação de acordo com seus requisitos.
Como Começar
Se você está interessado em experimentar o ansible-ibm-sterling com suporte para Kubernetes/OpenShift, você pode encontrar o repositório no GitHub. O repositório contém documentação detalhada, exemplos e scripts para ajudá-lo a começar.
Desde que finalizei o curso de Ciência da Computação em 1997, comecei a estudar muito mais que no próprio curso, sendo um especialista no que faço. Em 2019, deixei todo o conhecimento que tinha e tenho me reinventado continuamente através do aprendizado.
Nos últimos anos, aprendi sobre Kubernetes/OpenShift, Python, Ansible, MinIO, Kafka, Cloud functions, Angular, IBM Sterling, IBM Maximo (Gestão de Ativos), Cloud functions, etc. Isso me permitiu realizar, dentro da IBM, o trabalho que gosto de fazer e estar envolvido em diversos projetos e oportunidades.
Anualmente, lanço na minha avaliação a quantidade de horas de capacitação, e sempre acima de 200 horas de estudo e mais de 3 badges/certificações!
Existem muitas maneiras de aprender, que eu pratico todas:
E-Learning/Aulas Presenciais/Vídeos no Youtube
E-learning e treinamento em sala de aula são as formas mais óbvias quando se trata de aprendizado. Há muito material no IBM Your Learning e você pode obter muitos badges também. Mas você também pode aprender lendo e ouvindo (o que você pode registrar no Think 40 também, dependendo do conteúdo, eu diria). Existe muito material ruim no Youtube, mas existem excelentes vídeos de qualidade, procure sempre vídeos em Inglês e com mais de 30 minutos.
Leitura
Livros podem abrir sua mente. Ler ficção científica abre para mim um mundo de coisas que poderiam ser. Isso amplia sua mente. Permite que você pense fora da caixa. Ler livros relacionados a habilidades pessoais, também abre a sua mente. Audio-livros também são uma boa, pois você pode praticar uma atividade esportiva (correr/caminhar/academia) e se aprimorar.
Escutar
Você também pode aprender ouvindo podcasts. Há muitos podcasts sobre negócios, habilidades pessoais e liderança por aí. A partir desses podcasts, também aprendi sobre livros que essas pessoas leem ou documentários que são interessantes, hábitos diários que eles têm e que os ajudam.
Voluntariado (aprender fazendo)
Fiz trabalho voluntário compartilhando código e compartilhando no GitHub, trabalhando em demonstrações/provas de conceito no meu próprio tempo. Gostei de fazer isso, pois me deu a oportunidade de trabalhar com as tecnologias mais recentes e, assim, aprender fazendo. Novamente, isso me permite aprender apenas fazendo as coisas. Não sou desenvolvedor, mas gosto de desenvolver. Agora estou trabalhando com integração com ferramentas que, até algumas semanas atrás, eram apenas nomes para mim. Agora sei como usá-los. Na verdade, acho que esse tipo de trabalho voluntário traz o maior benefício. Como voluntário, você faz o que gosta de fazer (não necessariamente o trabalho para o qual foi treinado), aprende e também pratica a retribuição.
Encontrei muito poucos artigos que descreviam sobre problemas de performance ao utilizar LVM no Linux. Neste artigo explico o que é uma LVM e como identificar uma situação em que ela pode afetar o seu sistema.
O que é Logical Volume Management (LVM)?
O Logical Volume Management (LVM) é um recurso de extrema importância disponível no Kernel do Linux.
O LVM cria uma camada de software, que abstrai o storage/disco rígido e o sistema operacional, permitindo expandir ou reduzir a capacidade de armazenamento de um servidor de forma dinâmica, realizer snapshots, …
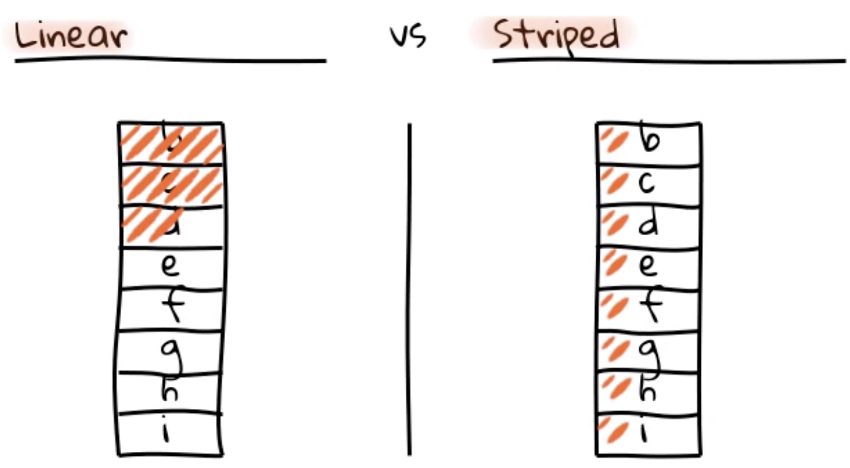
Existem três tipos de volumes lógicos LVM: volumes lineares, volumes Striped (distribuídos) e volumes espelhados. Vou descrever os dois primeiros:
LVM Lineares
Um volume linear agrega espaço de um ou mais volumes físicos em um volume lógico sequencialmente. Por exemplo, se você tiver dois discos de 60 GB, pode criar um volume lógico de 120 GB. O armazenamento físico é concatenado.
LVM Striped
Um volume Striped (distribuído) agrega espaço de um ou mais volumes físicos. Mas quando você grava dados em um LVM Striped, o sistema de arquivos distribui os dados nos volumes físicos subjacentes. O striping melhorar a eficiência da I/O de dados gravando e lendo em um número predeterminado de volumes físicos em paralelo.
Em resumo, nas LVM lineares a escrita é serial, isto é, vai ocupando os primeiros discos. Nas LVM Striped a escrita é divida entre os discos (riscos em Laranja).
Como identifica se o seu LVM é linear ou striped?
Por padrão no Linux, as LVM são lineares, a não ser que você especifique o tipo na hora da criação.
Utilize o comando lvs –segments para isso.
# lvs --segments
LV VG Attr #Str Type SSize
lv_docs vg_docs -wi-ao---- 1 linear 475.00g
lv_docs vg_docs -wi-ao---- 1 linear 475.00g
lv_docs vg_docs -wi-ao---- 1 linear 475.00g
lv_docs vg_docs -wi-ao---- 1 linear 475.00g
lv_docs vg_docs -wi-ao---- 1 linear 100.00g
Neste exemplo o disco é linear.
Situação na vida real
Em um episódio no trabalho, eu tive que investigar um problema de performance. Durante essa investigação, conseguimos identificar a seguinte situação no Sistema Operacional:
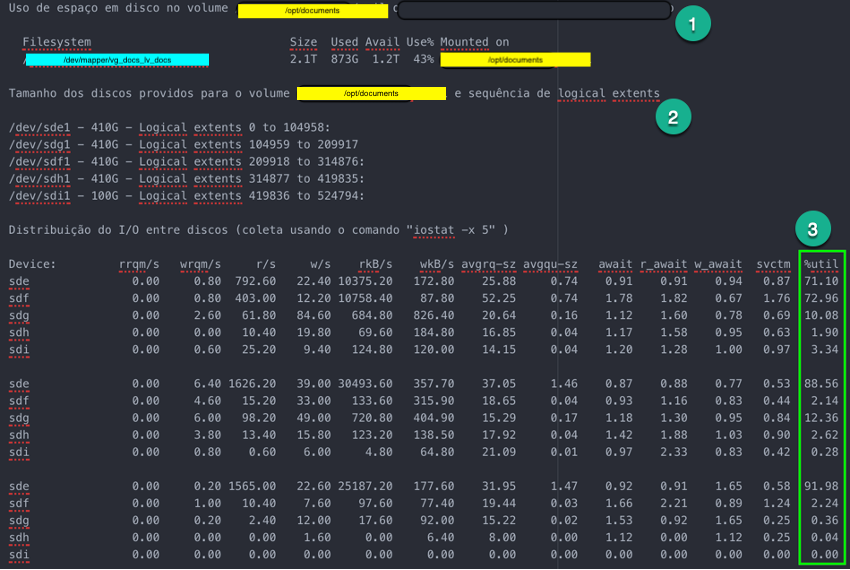
O Volume /opt/documents possuía 5 discos (4x450GB e 1x100GB) (item 2 na figura abaixo) e estávamos utilizando apenas 873GB de 2.1TB (item 1 na figura abaixo).
Analisando o volume /opt/documents, observamos que o I/O se concentrava em 3 dos 5 discos (item 3 na figura abaixo), sendo muito superior no disco /dev/sde1, início dos logical extents, e mínimo nos discos /dev/sdh1 e /dev/sdi1, final do logical extents (item 2 na figura abaixo).
Em função da formatação linear do volume e de como o SO cria os arquivos, ocorre a concentração do I/O no início do volume, não distribuindo igualmente a operações de leitura/escrita entre os discos.
Comandos utilizados
# df -h
# lsblk
# iostat -x 5
Isso pode acontecer na Nuvem?
A reposta é SIM . Esse artigo mostra o funcionamento e a perfomance entre volumes lineares vs striped no ambiente da AWS –> https://sysadmincasts.com/episodes/27-lvm-linear-vs-striped-logical-volumes
Concluindo, se o seu sistema tem um requisito que precise de armazenamento extremamente rápido em uma única máquina, você deve observar essa configuração da LVM. Ao usar LVM striped, normalmente quanto mais discos você tiver, melhor será o desempenho, isto é, se você precisar de 2TB de uma combinação de 10 discos de 200GB vai performar melhor que 5 discos de 400GB, independente ser os discos forem SSD ou não.
Em pesquisa de opinião da Stack Overflow, ela está entre as mais amadas por 4 anos seguidos e os desenvolvedores desejavam desenvolver com a linguagem Rust. Top!
Entre algumas características positivas do Rust temos:
* Código Nativo, você pode distribuir direto o seu binário. Aplicações como o npm foram desenvolvidas para rust.
* A linguagem e o compilador tentam Prever Problemas que acontecem em tempo de execução. Como eles tentam evitar um conjunto de erros e problemas comuns, a linguagem traz um conjunto de práticas que melhoram o seu estilo de programação.
* Rust tem o conceito de Ownership, isto é, um valor pode ser propriedade de apenas uma variável, quandoessa variável sair de contexto, o valor sai da memória, então NÃO tem Garbage Collection. Durante um Garbage Collection, a rotina verifica se tem alguém usando esse valor, o que tem um custo.
* Exceptions não coisas legais, em Rust você deve tratar as exceções.
* Ferramentas Modernas. O Rust, através do Cargo, já tem práticas modernas como Gerenciamento de Bibliotecas, Testes, Documentação, ….
* Rust está entre as melhores linguagem de programação para WebAssembly. O WebAssembly (abreviado Wasm) é um formato de instrução binário para execução nos Navegadores e Servidor de Aplicações.
Mas nem tudo são flores:
Algumas características negativas do Rust temos:
* Rust não é fácil de aprender.
* A linguagem ainda é nova, algumas features estão disponíveis apenas na versão nightly.
* Faltam items corporativos, isto é, senti falta de drivers para Banco de Dados.
Mas o que me chamou minha atenção sobre Rust é a possibilidade de economia que a sua performance e uso reduzido de memória pode trazer. Os provedores de nuvem definem suas unidades de processamento por flavors (sabores) de equipamentos levando em conta Cpu vs Memória. Uma aplicação que performa melhor terá influência direta no flavor utilizado e no valor da fatura no fim do mês. No artigo Parsing logs 230x faster with Rust – André.Arko.net, o autor descreve com como ele passou de US$ 1000,00 por mês para US$ 0 por mês, reescrevendo um script com Rust.
Se estiver disposto a arriscar, aprenda Rust. Comece desenvolvendo microsserviços, funções Lambda (Serverless), Scripts ou otimizando aplicações, através de uso de bibliotecas (.dll/.so), criadas em rust.
Não estou falando que Rust é a linguagem certa, mas acho que vale o investimento, você não estará sozinho.
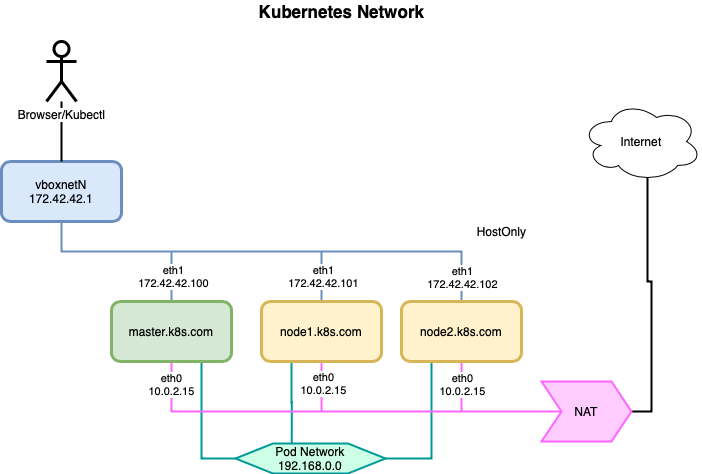
Montei um cluster Kubernetes com 3 nós no VirtualBox, sendo 1 master e 2 workers, usando o Vagrant e rodando o CentOS Linux 7.
Pra melhorar o entendimento do meu ambiente, montei um esquema da rede pra facilitar, veja abaixo:
Na virtual machine temos 2 interfaces de rede:
eth0 configurado como NAT e que tem acesso à internet
eth1 configurado com host only
O acesso ao cluster através da máquina host é através de uma interface vboxnetN, criado pelo VirtualBox:
Master node master.k8s.com com o ip 172.42.42.100 na interface eth1
Worker node 1 node1.k8s.com com o ip 172.42.42.101 na interface eth1
Worker node 2 node2.k8s.com com o ip 172.42.42.102 na interface eth1
Após você instalar a sua aplicação e expor o serviço, você pode acessar através de um browser, usando as urls https://172.42.42.100:<porta_servico>, https://172.42.42.101:<porta_servico>, https://172.42.42.102:<porta_servico> .
Se você quiser testar ou ver o código fonte, postei no meu GitHub https://github.com/ebasso/kubernetes-vagrant, também mostro como configurar o kubectl para acessar o ambiente. bye.