Encontrei muito poucos artigos que descreviam sobre problemas de performance ao utilizar LVM no Linux. Neste artigo explico o que é uma LVM e como identificar uma situação em que ela pode afetar o seu sistema.
O que é Logical Volume Management (LVM)?
O Logical Volume Management (LVM) é um recurso de extrema importância disponível no Kernel do Linux.
O LVM cria uma camada de software, que abstrai o storage/disco rígido e o sistema operacional, permitindo expandir ou reduzir a capacidade de armazenamento de um servidor de forma dinâmica, realizer snapshots, …
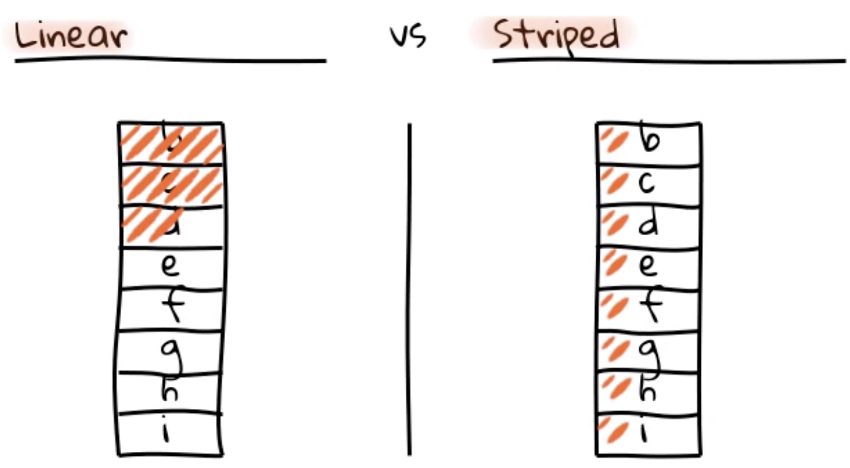
Existem três tipos de volumes lógicos LVM: volumes lineares, volumes Striped (distribuídos) e volumes espelhados. Vou descrever os dois primeiros:
- LVM Lineares
Um volume linear agrega espaço de um ou mais volumes físicos em um volume lógico sequencialmente. Por exemplo, se você tiver dois discos de 60 GB, pode criar um volume lógico de 120 GB. O armazenamento físico é concatenado.
- LVM Striped
Um volume Striped (distribuído) agrega espaço de um ou mais volumes físicos. Mas quando você grava dados em um LVM Striped, o sistema de arquivos distribui os dados nos volumes físicos subjacentes. O striping melhorar a eficiência da I/O de dados gravando e lendo em um número predeterminado de volumes físicos em paralelo.
Em resumo, nas LVM lineares a escrita é serial, isto é, vai ocupando os primeiros discos. Nas LVM Striped a escrita é divida entre os discos (riscos em Laranja).
Como identifica se o seu LVM é linear ou striped?
Por padrão no Linux, as LVM são lineares, a não ser que você especifique o tipo na hora da criação.
Utilize o comando lvs –segments para isso.
# lvs --segments LV VG Attr #Str Type SSize lv_docs vg_docs -wi-ao---- 1 linear 475.00g lv_docs vg_docs -wi-ao---- 1 linear 475.00g lv_docs vg_docs -wi-ao---- 1 linear 475.00g lv_docs vg_docs -wi-ao---- 1 linear 475.00g lv_docs vg_docs -wi-ao---- 1 linear 100.00g
Neste exemplo o disco é linear.
Situação na vida real
Em um episódio no trabalho, eu tive que investigar um problema de performance. Durante essa investigação, conseguimos identificar a seguinte situação no Sistema Operacional:
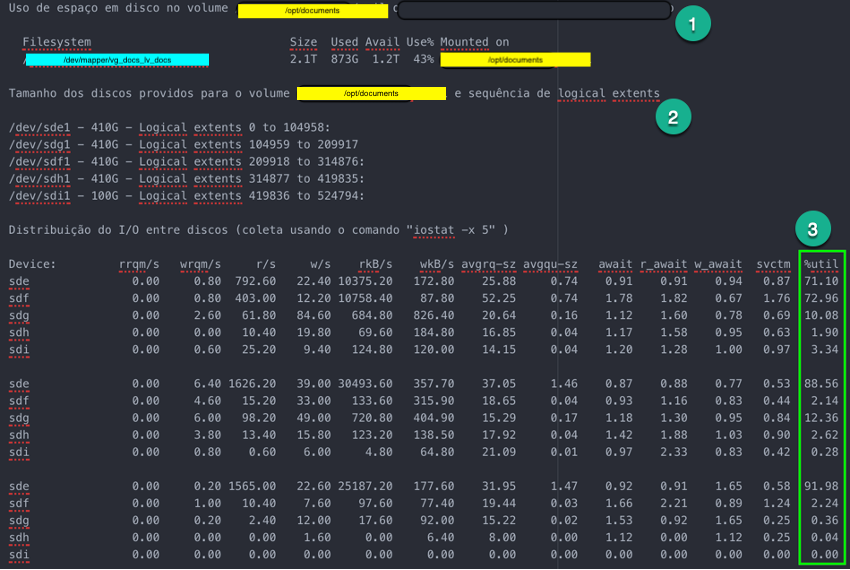
O Volume /opt/documents possuía 5 discos (4x450GB e 1x100GB) (item 2 na figura abaixo) e estávamos utilizando apenas 873GB de 2.1TB (item 1 na figura abaixo).
Analisando o volume /opt/documents, observamos que o I/O se concentrava em 3 dos 5 discos (item 3 na figura abaixo), sendo muito superior no disco /dev/sde1, início dos logical extents, e mínimo nos discos /dev/sdh1 e /dev/sdi1, final do logical extents (item 2 na figura abaixo).
Em função da formatação linear do volume e de como o SO cria os arquivos, ocorre a concentração do I/O no início do volume, não distribuindo igualmente a operações de leitura/escrita entre os discos.
Comandos utilizados
# df -h
# lsblk
# iostat -x 5Isso pode acontecer na Nuvem?
A reposta é SIM . Esse artigo mostra o funcionamento e a perfomance entre volumes lineares vs striped no ambiente da AWS –> https://sysadmincasts.com/episodes/27-lvm-linear-vs-striped-logical-volumes
Concluindo, se o seu sistema tem um requisito que precise de armazenamento extremamente rápido em uma única máquina, você deve observar essa configuração da LVM. Ao usar LVM striped, normalmente quanto mais discos você tiver, melhor será o desempenho, isto é, se você precisar de 2TB de uma combinação de 10 discos de 200GB vai performar melhor que 5 discos de 400GB, independente ser os discos forem SSD ou não.