A metodologia 12 factor consiste em um série métodos que você deve seguir para construir uma aplicação como Software-as-a-Service (SaaS).
Quando li sobre a 12-factor, ficou mais claro pra mim, como aplicações rodando em Cloud estão organizadas em provedores como Amazon AWS, Microsoft Azure, IBM Bluemix ou como soluções Cloud Foundry.
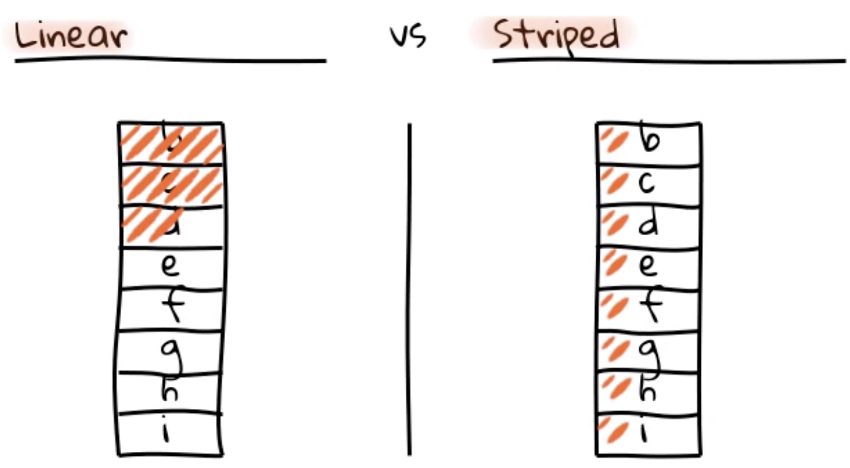
Fator 1 – Um código base em um repositório com multiplos deployments.
Utilize de um sistema de controle de versão como Git ou Subversion, e a partir deste código fonte faça o deploy em múltiplos lugares, como ambiente de desenvolvimento, homologação e produção.
Fator 2 – Declare e separa as dependências.
As dependências da aplicação devem estar fora do código fonte. Por exemplo, no arquivo package.json para uma aplicação em Node.js.
Com isso, o deploy de uma aplicação pode ser feito em diversos servidores, e assim não nos preocupamos com as suas dependências.
Fator 3 – Armazene configuraçòes no seu ambiente.
As configurações da aplicação devem estar fora do código fonte. Nos principais provedores de Cloud, essas configurações são declaradas como variáveis de ambiente.
Exemplo:
set PORT “8080”
set JDBC_URL “jdbc://db_server:port/”
Fator 4 – Trate serviços de apoio como recursos anexado.
Um serviço de apoio é qualquer serviço que a aplicação faça através da rede. Exemplos: Banco de dados (MySql/MongoDB), Sistemas de Mensagens/Filas, serviços SMTP para emails externos (tais como Postfix), e serviços do IBM Watson.
Você deve preparar sua aplicação para usar estes serviços independente do local onde estejam (local ou remoto), e usar variáveis de ambiente para alterar essas configurações. Podendo usar Web UI dashboard do provedor Cloud ou comandos como “cf create-service” e “cf bind-service” para ligar os serviços.
Fator 5 – Faça a separação do Build, Release and Run.
Separe as fases de:
- Build = Pegue uma versão do código do repositório, forneça as dependências, compile binários e empacote.
- Release = Envie o Build para um servidor, ajuste as configurações necessárias para que ele seja executado.
- Run = Rode a aplicação no ambiente de execução, através do início de alguns dos processos da aplicação, para que ele esteja disponível para os usuários acessarem.
Fator 6 – Execute a aplicação como um ou mais processos stateless
Execute a aplicação como um ou mais processos que não armazenam estado.
Quando você cria aplicativos, use vários processos ou serviços conforme necessário.
Evite dependências em stick sessions e mantenha os dados da sessão em um armazenamento persistente para garantir que o tráfego possa ser roteado para outros processos sem interrupção do serviço.
Fator 7 – Exporte de serviços pela porta de TCP/IP
A aplicação lê a variável de ambiente e exporta o serviço através do bind a uma porta de TCP/IP, que recebe as requisições que chegam na mesma.
Depois você pode adicionar um servidor Nginx, que faz um proxy para esse serviço ou utilizar o serviço de roteamento de tráfico do seu provedor cloud.
Fator 8 – Escale atráves do uso de um processo modelo.
Escale horizontalmente a sua aplicação através da criação de processos modelos. Por exemplo, solicitações HTTP podem ser manipuladas para um processo web, e tarefas background de longa duração podem ser manipuladas por um processo trabalhador.
Fator 9 – Maximize a robustez com inicialização e desligamento rápido
Processos no 12-factor são descartáveis, significando que podem ser iniciados ou parados a qualquer momento. Um processo dever iniciar rapidamente, fazendo
o mínimo de ações. E quando o processo for encerrado, deve seguir o mesmo padrão.
Isso facilita o escalonamento, rápido deploy de código ou mudanças de configuração, e robustez de deploys de produção.
Fator 10 – Mantenha os ambientes de desenvolvimento, homologação, produção o mais semelhante possível
Manter ambientes semelhantes evita erros durante o processo de envio da aplicação para produção.
Ferramentas como Docker, Puppet auxiliam nisso. Outras soluções com Spaces no IBM Bluemix provem metodos efetivos para separar diferentes níveis da aplicação.
Esta abordagem permite a entrega de software ágil ( Agile Software) e a integração contínua (continuous integration).
Fator 11 – Trate logs como fluxo de eventos
Utilize os logs da aplicação para entender o funcionamento e utilização da sua aplicação.
A aplicação deve enviar as mensagens para a saída padrão e esta deve ser redirecionada para locais específicos de acordo com o ambiente onde a aplicação está executando, em desenvolvimento para um arquivo.
Exemplo: No Bluemix ou Cloud Foundry, o Loggregator coleta os dados de log em vários componentes do aplicativo e você pode visualizar atráves do comando cf logs.
Fator 12: Executar tarefas de administração/gerenciamento como processos pontuais
Crie tarefas que precisam ser executadas uma vez ou ocasionalmente em componentes separados que podem ser executados quando necessário em vez de adicionar o código diretamente em outro componente.
Por exemplo, se um aplicativo precisa migrar dados para um banco de dados, coloque essa tarefa em um componente separado ao invés de adicioná-lo ao código principal do aplicativo na inicialização.
E aí. Vai utilizar a metodologia 12-factor na sua próxima aplicação?
Leia também: