Não vou explicar conceitos do Kubernetes, pois não é o meu foco aqui, a idéia é comparar com o modelo tradicional afim de entender melhor o Kubernetes.
Se você precisa expor qualquer serviço executando dentro de um cluster Kubernetes, você deve utilizar o Ingress.
Para explicar de forma rápida o Ingress, montei o seguinte diagrama:
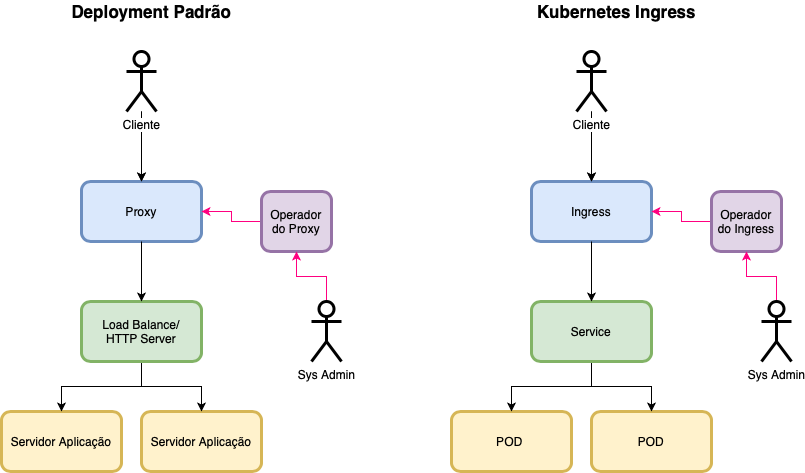
Você deve pensar no Ingress, como um típico Proxy Reverso que colocamos na DMZ, para permitir acesso à sua aplicações que ficam na Intranet. No modelo tradicional usariamos um Apache HTTP server ou um Nginx, pra controlar o tráfego e proteger contra ataques da Internet.
Em um ambiente Java tradicional, teríamos um Load Balancer ou um HTTP Server na frente dos Servidores de Aplicação, mas no Kubernetes temos as figuras do Service e dos PODs, respectivamente.
Adicionei a personagem do Operado de Proxy, que seria do Admin que faz alteração no arquivo .conf. Já no K8s, essa tarefa é executada através do comando kubectl. Podendo usar o linha de comando ou através de um arquivo yaml.
Acredito que tenho deixado mais claro o funcionamento do Ingress. Bye.